



PS:以下都是我在面试过程中根据我的简历所问的或者可能问的面试题,建议找工作的自己也按照自己的简历多面试一下积累下面试经验。
一、Java基础
1. 泛型
1.1. 什么是泛型?泛型的作用?
Java 泛型(Generics)是 JDK 5 中引入的一个新特性。
使用泛型参数,可以增强代码的可读性以及稳定性。编译器可以对泛型参数进行检测,并且通过泛型参数可以指定传入的对象类型。比如
ArrayList<Persion> persons = new ArrayList<String>()这行代码就指明了该ArrayList对象只能传入Persion对象,如果传入其他类型的对象就会报错。可以用于构建泛型集合。原生
List返回类型是Object,需要手动转换类型才能使用,使用泛型后编译器自动转换。
1.2. 泛型的使用方式有哪几种?
java 中泛型标记符:
E - Element (在集合中使用,因为集合中存放的是元素)
T - Type(Java 类)
K - Key(键)
V - Value(值)
N - Number(数值类型)
? - 表示不确定的 java 类型
泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。
泛型类:
//在实例化泛型类时,必须指定T的具体类型
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}如何实例化泛型类:
Generic<Integer> genericInteger = new Generic<Integer>(123456);泛型接口 :
public interface Generator<T> {
public T method();
}实现泛型接口,不指定类型:
class GeneratorImpl<T> implements Generator<T>{
@Override
public T method() {
return null;
}
}实现泛型接口,指定类型:
class GeneratorImpl<T> implements Generator<String>{
@Override
public String method() {
return "hello";
}
}泛型方法 :
public static <E> void printArray(E[] inputArray ){
for (E element : inputArray){
System.out.printf( "%s ", element );
}
System.out.println();
}// 创建不同类型数组: Integer, String
Integer[] intArray = {1, 2, 3 };
String[] stringArray = {"Hello", "World" };
printArray(intArray);
printArray(stringArray);1.3. 项目中哪里用到了泛型?
可用于定义通用返回结果
CommonResult<T>通过参数T可根据具体的返回类型动态指定结果的数据类型定义
Excel处理类ExcelUtil<T>用于动态指定Excel导出的数据类型用于构建集合工具类。参考
Collections中的sort, binarySearch方法
1.4. 什么是泛型擦除机制?为什么要擦除?
Java 的泛型是伪泛型,这是因为 Java 在编译期间,所有的泛型信息都会被擦掉,这也就是通常所说类型擦除 。
编译器会在编译期间动态将泛型 T 擦除为 Object 或将 T extends xxx 擦除为其限定类型 xxx
泛型本质上是编译器的行为,为了保证引入泛型机制但不创建新的类型,减少虚拟机的运行开销,所以通过擦除将泛型类转化为一般类。
这里说的可能有点抽象,我举个例子:
List<Integer> list = new ArrayList<>();
list.add(12);
// 1. 编译期间直接添加会报错
list.add("a");
Class<? extends List> clazz = list.getClass();
Method add = clazz.getDeclaredMethod("add", Object.class);
// 2. 运行期间通过反射添加,是可以的
add.invoke(list, "kl");
// 输出12
System.out.println(list.get(0));
// 输出kl
System.out.println(list.get(1));并不是所有类型都会转换为java.lang.Object,比如如果是String类型,则参数类型依旧是java.lang.String。
1.5. 既然编译器要把泛型擦除,那为什么还要用泛型呢?用Object代替不行吗? 该题变相考察泛型的作用。
可在编译期间进行类型检测。
使用 Object 类型需要手动添加强制类型转换,降低代码可读性,提高出错概率
泛型可以使用自限定类型。如 T extends Comparable 还能调用 compareTo(T o) 方法 ,Object
则没有此功能
1.6. 什么是桥方法?
桥方法(Bridge Method) 用于继承泛型类时保证多态。注意桥方法为编译器自动生成,非手写。
class Node<T> {
public T data;
public Node(T data) {
this.data = data;
}
public void setData(T data) {
System.out.println("Node.setData");
this.data = data;
}
}
class MyNode extends Node<Integer> {
public MyNode(Integer data) {
super(data);
}
// Node<T> 泛型擦除后为 setData(Object data),而子类 MyNode 中并没有重写该方法,所以编译器会加入该桥方法保证多态
// 编译器自动生成
public void setData(Object data) {
setData((Integer) data);
}
public void setData(Integer data) {
System.out.println("MyNode.setData");
super.setData(data);
}
}1.7. 泛型有哪些限制?为什么?
泛型的限制一般是由泛型擦除机制导致的。擦除为 Object 后无法进行类型判断
只能声明不能实例化 T 类型变量
泛型参数不能是基本类型。因为基本类型是 Object 子类,应该用基本类型对应的引用类型代替
不能实例化泛型参数的数组。擦除后为 Object 后无法进行类型判断
不能实例化泛型数组
泛型无法使用 Instance of 和 getClass() 进行类型判断
不能抛出和捕获 T 类型的异常。可以声明
不能实现两个不同泛型参数的同一接口,擦除后多个父类的桥方法将冲突
不能使用static修饰泛型变量
1.8. 以下代码是否能编译,为什么?
public final class Algorithm {
public static <T> T max(T x, T y) {
return x > y ? x : y;
}
}
无法编译,因为 x 和 y 都会被擦除为 Object 类型, Object 无法使用 > 进行比较
public class Singleton<T> {
public static T getInstance() {
if (instance == null)
instance = new Singleton<T>();
return instance;
}
private static T instance = null;
}无法编译,不能使用 static 修饰泛型 T
List<String>[] ls = new ArrayList<String>[10];无法编译,不能实例化泛型数组
List<String>[] ls = new ArrayList[10];可以编译,使用原始类型:new ArrayList[10]创建的是原始类型数组,没有泛型信息,向后兼容:这是Java 5之前就存在的语法。
1.9. Array中可以用泛型吗
在Java中,数组本身不能直接使用泛型作为元素类型,数组在运行时需要知道确切类型信息(称为"reified"类型),泛型由于类型擦除,运行时无法提供足够类型信息,可能导致类型不安全操作(可能抛出ArrayStoreException)
2. 通配符
通配符(Wildcard)是Java泛型中的?符号,用来表示未知类型,主要解决泛型类型不变性带来的灵活性问题。
2.1. 通配符 ? 和常用的泛型 T 之间有什么区别?
T 可以用于声明变量或常量而
?不行T 一般用于声明泛型类或方法,通配符
?一般用于泛型方法的调用代码和形参T 在编译期会被擦除为限定类型或 Object,通配符用于捕获具体类型
2.2. 无界通配符 ? 的作用?
接受任何泛型类型数据
实现不依赖于具体类型参数的简单方法,如非空判断,size(),clear() 等方法
用于捕获参数类型并交由泛型方法进行处理
2.3. 上界通配符 ? extends T和下界通配符 ? super T 有什么区别?使用场景?
使用
? extends T申明的泛型参数只能调用 get() 方法返回 T 类型,调用 set() 报错。使用 ?super T声明的泛型参数只能调用 set() 方法接收 T类型,调用 get() 报错。它们所接收参数的范围不同,详细见上图
根据
PECS原则,即producer-extends consumer-super如果参数化类型表示一个生产者,就用?extends xxx声明,如果表示一个消费者,就用? super xxx声明
2.4. T extends xxx 和 ? extends xxx 又有什么区别?
T extends xxx 用于定义泛型类和方法,擦除后为 xxx 类型, ? extends xxx 用于声明方法形参,接收 xxx 和其子类型
2.5. 以下代码是否能编译,为什么?
class Shape {
/* ... */ }
class Circle extends Shape {
/* ... */ }
class Rectangle extends Shape {
/* ... */ }
class Node<T> {
/* ... */ }
Node<Circle> nc = new Node<>();
Node<Shape> ns = nc;不能,因为Node<Circle> 不是 Node<Shape> 的子类
class Shape {
/* ... */ }
class Circle extends Shape {
/* ... */ }
class Rectangle extends Shape {
/* ... */ }
class Node<T> {
/* ... */ }
class ChildNode<T> extends Node<T>{
}
ChildNode<Circle> nc = new ChildNode<>();
Node<Circle> ns = nc;可以编译,ChildNode<Circle> 是 Node<Circle> 的子类
public static void print(List<? extends Number> list) {
for (Number n : list)
System.out.print(n + " ");
System.out.println();
}可以编译,List 可以往外取元素,但是无法调用 add() 添加元素
3. 反射
3.1 什么是Java反射机制?
Java的反射(reflection)机制是指在程序的运行状态中,可以构造任意一个类的对象,可以了解任意一个对象所属的类,可以了解任意一个类的成员变量和方法,可以调用任意一个对象的属性和方法。 这种动态获取程序信息以及动态调用对象的功能称为Java语言的反射机制。
3.2 除了使用new创建对象之外,还可以用什么方法创建对象?
使用Java反射可以创建对象。
// 使用Class.newInstance()(JDK9已废弃)
Class<?> clazz = Class.forName("java.lang.String");
String str = (String) clazz.newInstance();
// 使用Constructor.newInstance()(推荐)
Constructor<String> constructor = String.class.getConstructor(String.class);
String str = constructor.newInstance("Hello");3.3 Java反射创建对象效率高还是通过new创建对象的效率高?
通过new创建对象的效率比较高。通过反射时,先找查找类资源,使用类加载器创建,过程比较繁琐,所以效率较低.
3.4 java反射的作用?
反射机制是在运行时,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意个对象,都能够调用它的任意一个方法。在java中,只要给定类的名字,就可以通过反射机制来获得类的所有信息。
这种动态获取的信息以及动态调用对象的方法的功能称为Java语言的反射机制
在运行时判定任意一个对象所属的类
在运行时构造任意一个类的对象
在运行时判定任意一个类所具有的成员变量和方法
在运行时调用任意一个对象的成员变量和 方法
在运行调用任意一个对象的方法
生成动态代码
3.5 哪些地方会用到反射?
JDBC中,利用反射动态加载数据库驱动程序

Web服务器中利用反射调用Servlet的服务方法
框架用到反射机制,注入属性,调用方法,如Spring
3.6 反射的实现方法?
Class.forName(“类的路径”)
类名.class
对象名.getClass()
基本类型的包装类,可以调用包装类的Type属性来获得该包装类的Class对象
3.7 反射机制有哪些优缺点?
优点:
能够运行时动态获取类的实例,提高灵活性;
与动态编译结合
缺点:
使用反射性能较低,需要解析字节码,将内存中的对象进行解析。
解决方案:
通过setAccessible(true)关闭JDK的安全检查来提升反射速度;
多次创建一个类的实例时,有缓存会快很多
ReflflectASM工具类,通过字节码生成的方式加快反射速度
相对不安全,破坏了封装性(因为通过反射可以获得私有方法和属性)
3.8 Java反射API
反射 API 用来生成 JVM 中的类、接口或则对象的信息
Class 类:反射的核心类,可以获取类的属性,方法等信息。
Field 类:Java.lang.reflec 包中的类,表示类的成员变量,可以用来获取和设置类之中的属性
值。Method 类: Java.lang.reflec 包中的类,表示类的方法,它可以用来获取类中的方法信息或
者执行方法。Constructor 类: Java.lang.reflec 包中的类,表示类的构造方法。
3.9 反射使用步骤(获取 Class 对象、调用对象方法)
获取想要操作的类的 Class 对象,他是反射的核心,通过 Class 对象我们可以任意调用类的方法。
调用 Class 类中的方法,既就是反射的使用阶段。
使用反射 API 来操作这些信息。
3.10 获取 Class 对象有几种方法
调用某个对象的 getClass()方法
Person p=new Person(); Class clazz=p.getClass();调用某个类的 class 属性来获取该类对应的 Class 对象
Class clazz=Person.class;使用 Class 类中的 forName() 静态方法(最安全/性能最好)
Class clazz=Class.forName("类的全路径"); //JDK8最常用(JDK9已废弃)当我们获得了想要操作的类的 Class 对象后,可以通过 Class 类中的方法获取并查看该类中的方法和属性。
//获取 Person 类的 Class 对象 Class clazz=Class.forName("reflection.Person"); //获取 Person 类的所有方法信息 Method[] method=clazz.getDeclaredMethods(); for(Method m:method){ System.out.println(m.toString()); } //获取 Person 类的所有成员属性信息 Field[] field=clazz.getDeclaredFields(); for(Field f:field){ System.out.println(f.toString()); } //获取 Person 类的所有构造方法信息 Constructor[] constructor=clazz.getDeclaredConstructors(); for(Constructor c:constructor){ System.out.println(c.toString()); }
3.11 利用反射动态创建对象实例
Class 对象的 newInstance()
使用 Class 对象的 newInstance()方法来创建该 Class 对象对应类的实例,但是这种方法要求该 Class 对象对应的类有默认的空构造器。
调用 Constructor 对象的 newInstance()
先使用 Class 对象获取指定的 Constructor 对象,再调用 Constructor 对象的 newInstance()方法来创建 Class 对象对应类的实例,通过这种方法可以选定构造方法创建实例。
//获取 Person 类的 Class 对象 Class clazz=Class.forName("reflection.Person"); //使用.newInstane 方法创建对象 Person p=(Person) clazz.newInstance(); //获取构造方法并创建对象 Constructor c=clazz.getDeclaredConstructor(String.class,String.class,int.class); //创建对象并设置属性13/04/2018 Person p1=(Person) c.newInstance("李四","男",20);
4. 异常
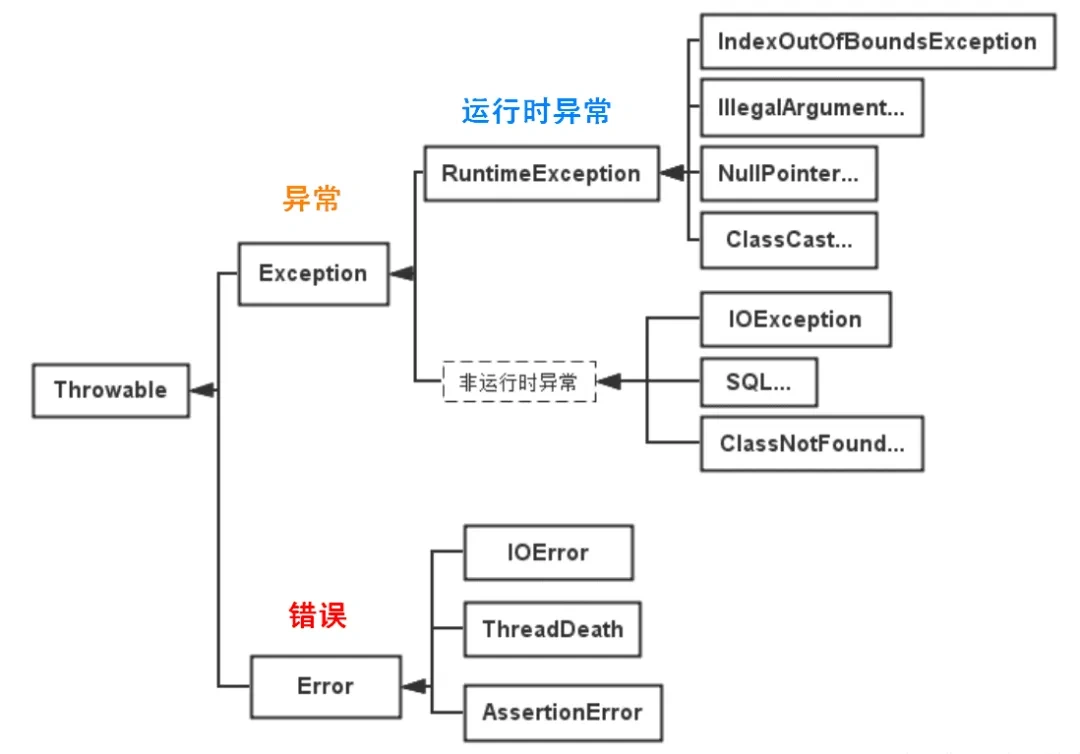
4.1 Java 中异常分为哪些种类?
按照异常需要处理的时机分为编译时异常(也叫强制性异常)也叫 CheckedException 和运行时异常(也叫非强制性异常)也叫RuntimeException。 只有 java 语言提供了 Checked 异常,Java 认为 Checked异常都是可以被处理的异常,所以 Java 程序必须显式处理 Checked 异常。如果程序没有处理 Checked 异常,该程序在编译时就会发生错误无法编译。这体现了 Java 的设计哲学:没有完善错误处理的代码根本没有机会被执行。 对 Checked 异常处理方法有两种:
当前方法知道如何处理该异常,则用 try...catch 块来处理该异常。
当前方法不知道如何处理,则在定义该方法是声明抛出该异常。
运行时异常只有当代码在运行时才发行的异常,编译时不需要 try catch。Runtime 如除数是 0 和数组下标越界等,其产生频繁,处理麻烦,若显示申明或者捕获将会对程序的可读性和运行效率影响很大。所以由系统自动检测并将它们交给缺省的异常处理程序。当然如果你有处理要求也可以显示捕获它们。
4.2 调用下面的方法,得到的返回值是什么?
分析:
代码走到第3行的时候,遇到了一个 MathException,因此第4行不会执行了,代码跳到catch里面
代码走到第6行的时候,异常机制有这么一个原则:如果在 catch 中遇到了 return 或者异常等能使该函数终止的话,那么有 finally 就必须先执行完 finally 代码块里面的代码,然后再返回值。因此跳到第8行。
第8行是一个return语句,这个时候就结束了,第6行的值无法被返回。返回值为3.
若第8行不是一个return语句,而是一个释放资源的操作,则返回值为2.
4.3 Error 和 Exception 区别是什么?
Error 类型的错误通常为虚拟机相关错误,如系统崩溃,内存不足,堆栈溢出等,编译器不会对这类错误进行检测,JAVA 应用程序也不应对这类错误进行捕获,一旦这类错误发生,通常应用程序会被终止,仅靠应用程序本身无法恢复;
Exception 类的错误是可以在应用程序中进行捕获并处理的,通常遇到这种错误,应对其进行处理,使应用程序可以继续正常运行。
4.4 运行时异常和一般异常(受检异常)区别是什么?
运行时异常包括 RuntimeException 类及其子类,表示 JVM 在运行期间可能出现的异常。Java 编译器不会检查运行时异常。
受检异常是Exception 中除 RuntimeException 及其子类之外的异常。Java 编译器会检查受检异常。
RuntimeException异常和受检异常之间的区别:是否强制要求调用者必须处理此异常,如果强制要求调用者必须进行处理,那么就使用受检异常,否则就选择非受检异常(RuntimeException)。
一般来讲,如果没有特殊的要求,我们建议使用RuntimeException异常。
4.5 throw 和 throws 的区别是什么?
throw:
throw 语句用在方法体内,表示抛出异常,由方法体内的语句处理。
throw 是具体向外抛出异常的动作,所以它抛出的是一个异常实例,执行 throw 一定是抛出了某种异常。
throws:
throws 语句是用在方法声明后面,表示如果抛出异常,由该方法的调用者来进行异常的处理。
throws 主要是声明这个方法会抛出某种类型的异常,让它的使用者要知道需要捕获的异常的类型。
throws 表示出现异常的一种可能性,并不一定会发生这种异常。
4.6 final、finally、finalize 的区别?
final:可用于修饰属性、方法、类。修饰的属性不可变(不能重新被赋值),方法不能重写,类不能继承。
finally:异常处理语句try-catch的一部分,一般将一定要执行的代码放在finally代码块中,总是被执行,一般用来存放一些关闭资源的操作。
finalize:Object 类的一个方法,在垃圾回收器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等。该方法更像是一个对象生命周期的临终方法,当该方法被系统调用则代表该对象即将“死亡”,但是需要注意的是,我们主动行为上去调用该方法并不会导致该对象“死亡”,这是一个被动的方法(其实就是回调方法),不需要我们调用。
4.7 常见的 RuntimeException 有哪些?
ClassCastException:数据类型转换异常
IndexOutOfBoundsException:数组下标越界异常,常见于操作数组对象时发生。
NullPointerException:空指针异常;出现原因:调用了未经初始化的对象或者是不存在的对象。
ClassNotFoundException:指定的类找不到;出现原因:类的名称和路径加载错误;通常都是程序试图通过字符串来加载某个类时可能引发异常。
NumberFormatException:字符串转换为数字异常;出现原因:字符型数据中包含非数字型字符。
IllegalArgumentException:方法传递参数异常
NoClassDefFoundException:未找到定义类异常
SQLException SQL:常见于操作数据库时的 SQL 语句错误。
InstantiationException:实例化异常。
NoSuchMethodException:方法不存在异常
ArrayStoreException:数据存储异常,操作数组时类型不一致
还有IO操作的BufferOverflowException异常
4.8 finally内存回收的情况?
如果在try... catch 部台用Connection 对象连接了数据库,而且在后继部台不会再用到这个连接对象,那么一定要在 finally从句中关闭该连接对象, 否则i亥连接对象所占用的内存资源无法被回收。
如果在try... catch 部分用到了一些IO对象进行了读写操作,那么也一定要在finally 中关闭这些IO对象,否则,IO对象所占用的内存资源无法被回收。
如果在try .catch 部分用到了ArrayList 、Linkedlist 、Hash Map 等集合对象,而且这些对象之后不会再被用到,那么在finally中建议通过调用clear方法来清空这些集合。
例如,在try .catch 语句中育一个对象obj 指向7一块比较大的内存空间(假设100MB) ,而且之后不会再被用到,那么在 finally 从句中建议写上 obj=null,这样能提升内存使用效率。
4.9 异常的设计原则有哪些?
不要将异常处理用于正常的控制流
对可以恢复的情况使用受检异常,对编程错误使用运行时异常
避免不必要的使用受检异常
优先使用标准的异常
每个方法抛出的异常都要有文档
保持异常的原子性
不要在 catch 中忽略掉捕获到的异常
二、Java集合
三、Java并发
进程(Process)是什么:程序的独立运行实例(如同时开两个Chrome就是两个进程)
核心特点:
拥有独立的内存空间(互相隔离)
系统资源分配的基本单位(CPU、磁盘、网络等)
创建/销毁开销大
线程(Thread)是什么:进程内的执行单元(一个进程可以有多个线程)
核心特点:
共享进程的内存(可直接读写全局变量)
CPU调度的基本单位(内核管理)
创建/销毁比进程轻量,但仍需系统调用
协程(Coroutine)是什么:用户态轻量级线程(程序自己调度的“微线程”)
核心特点:
完全在用户态运行(不归内核管)
切换成本极低(无需系统调用)
一个线程可跑数万协程
1、多线程
线程的创建方式有哪些?
1.继承Thread类
这是最直接的一种方式,用户自定义类继承java.lang.Thread类,重写其run()方法,run()方法中定义了线程执行的具体任务。创建该类的实例后,通过调用start()方法启动线程。
class MyThread extends Thread {
@Override
public void run() {
// 线程执行的代码
}
}
public static void main(String[] args) {
MyThread t = new MyThread();
t.start();
}
采用继承Thread类方式
优点: 编写简单,如果需要访问当前线程,无需使用Thread.currentThread ()方法,直接使用this,即可获得当前线程
缺点:因为线程类已经继承了Thread类,所以不能再继承其他的父类
2.实现Runnable接口
如果一个类已经继承了其他类,就不能再继承Thread类,此时可以实现java.lang.Runnable接口。实现Runnable接口需要重写run()方法,然后将此Runnable对象作为参数传递给Thread类的构造器,创建Thread对象后调用其start()方法启动线程。
class MyRunnable implements Runnable {
@Override
public void run() {
// 线程执行的代码
}
}
public static void main(String[] args) {
Thread t = new Thread(new MyRunnable());
t.start();
}
采用实现Runnable接口方式:
优点:线程类只是实现了Runable接口,还可以继承其他的类。在这种方式下,可以多个线程共享同一个目标对象,所以非常适合多个相同线程来处理同一份资源的情况,从而可以将CPU代码和数据分开,形成清晰的模型,较好地体现了面向对象的思想。
缺点:编程稍微复杂,如果需要访问当前线程,必须使用Thread.currentThread()方法。
实现Callable接口与FutureTask
java.util.concurrent.Callable接口类似于Runnable,但Callable的call()方法可以有返回值并且可以抛出异常。要执行Callable任务,需将它包装进一个FutureTask,因为Thread类的构造器只接受Runnable参数,而FutureTask实现了Runnable接口。
class MyCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
// 线程执行的代码,这里返回一个整型结果
return 1;
}
}
public static void main(String[] args) {
MyCallable task = new MyCallable();
FutureTask<Integer> futureTask = new FutureTask<>(task);
Thread t = new Thread(futureTask);
t.start();
try {
Integer result = futureTask.get(); // 获取线程执行结果
System.out.println("Result: " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
采用实现Callable接口方式:
缺点:编程稍微复杂,如果需要访问当前线程,必须调用Thread.currentThread()方法。
优点:线程只是实现Runnable或实现Callable接口,还可以继承其他类。这种方式下,多个线程可以共享一个target对象,非常适合多线程处理同一份资源的情形。
使用线程池(Executor框架)
从Java 5开始引入的java.util.concurrent.ExecutorService和相关类提供了线程池的支持,这是一种更高效的线程管理方式,避免了频繁创建和销毁线程的开销。可以通过Executors类的静态方法创建不同类型的线程池。
class Task implements Runnable {
@Override
public void run() {
// 线程执行的代码
}
}
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(10); // 创建固定大小的线程池
for (int i = 0; i < 100; i++) {
executor.submit(new Task()); // 提交任务到线程池执行
}
executor.shutdown(); // 关闭线程池
}
采用线程池方式:
缺点:程池增加了程序的复杂度,特别是当涉及线程池参数调整和故障排查时。错误的配置可能导致死锁、资源耗尽等问题,这些问题的诊断和修复可能较为复杂。
优点:线程池可以重用预先创建的线程,避免了线程创建和销毁的开销,显著提高了程序的性能。对于需要快速响应的并发请求,线程池可以迅速提供线程来处理任务,减少等待时间。并且,线程池能够有效控制运行的线程数量,防止因创建过多线程导致的系统资源耗尽(如内存溢出)。通过合理配置线程池大小,可以最大化CPU利用率和系统吞吐量。
Java线程的状态有哪些?
java.lang.Thread.State枚举类中定义了六种线程的状态,可以调用线程Thread中的getState()方法获取当前线程的状态。
四、Java虚拟机
Java相关的面试题
本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。